The Definitive Guide to API Test Automation With Playwright: Part 5 - Calculating API Endpoint Coverage

Now that I have some decent coverage around the auth and bookings endpoints, I have a new challenge. How do I keep up with what areas need coverage added, and how do I know if a a new auth endpoint gets added, without manually checking the docs every day. Today's article will show you the solution that I use. Before we get going too far, big shoutout to Joel Black and Sergei Gapanovich for the inspiration and refinement of this approach.
If you missed the Introduction, Part 1, Part 2, Part 3, or Part 4 I encourage you to check those out to get the context of where we are jumping in.
High Level Approach and Plan
I want to be able to leverage the OpenAPI spec files that are provided and compare them against the API tests we have already created to figure out where our gaps are. This will require:
- Tagging our tests with the endpoint(s) that are being covered
- Downloading the OpenAPI spec file for the endpoints we want to check
- Parsing the OpenAPI spec file and matching them with our tagged tests
- Calculating coverage and console.log() the results
- This should all happen prior to any tests running
With this approach I should have a good idea of what areas need coverage, and if there are any new endpoints added to the OpenAPI spec file we are monitoring anytime the tests run.
Coverage Tags
The idea behind a coverage tag is to create a unique identifier that represents the API endpoint. An example of a coverage tag I use is //COVERAGE_TAG: POST /auth/login This includes //Coverage_TAG: which allows me to use grep to search for the specific line, the POST is the verb/action and the /auth/login is the endpoint I am testing. Depending on your specific system under test you may need to adjust the endpoint url based on what you have accessible in your OpenAPI spec file.
The example provided below can be found in the booking.get.spec.ts file. One thing to note, is in the spec file I cover 3 different endpoints. With the approach on calculating coverage, I filter out any duplicate coverage tags, so if there were other examples with the same endpoints covered they wouldn't get counted twice.
//COVERAGE_TAG: GET /booking/
//COVERAGE_TAG: GET /booking/{id}
//COVERAGE_TAG: GET /booking/summary
import { test, expect } from "@playwright/test";
import { isValidDate } from "../../lib/helpers/date";
import {
createHeaders,
createInvalidHeaders,
} from "../../lib/helpers/createHeaders";
test.describe("booking/ GET requests", async () => {
let headers;
let invalidHeader;
...
I typically will put the coverage tags at the top of the file, though technically you could put it anywhere within the file.
Downloading and Parsing an OpenAPI Spec File
The next step we need to do is to download the OpenAPI spec file. This file will be the source of truth for what endpoints exist. I won't go super deep into the OpenAPI Specification but a quick overview from the website:
The OpenAPI Specification (OAS) defines a standard, programming language-agnostic interface description for HTTP APIs, which allows both humans and computers to discover and understand the capabilities of a service without requiring access to source code, additional documentation, or inspection of network traffic. When properly defined via OpenAPI, a consumer can understand and interact with the remote service with a minimal amount of implementation logic. Similar to what interface descriptions have done for lower-level programming, the OpenAPI Specification removes guesswork in calling a service.

For our purposes we will utilize this file to identify the verbs and endpoints that are published in the OpenAPI spec file. It's possible your system under test doesn't have OpenAPI spec file, but there may still be hope. if there is a swagger doc, there is more than likely some sort of json that can be downloaded that can be parsed to get similar information you'll just have to work out the logic for yourself.
Swagger UI Pages
- Auth Swagger UI - https://automationintesting.online/auth/swagger-ui/index.html#/
- Room Swagger UI - https://automationintesting.online/room/swagger-ui/index.html#/
- Branding Swagger UI - https://automationintesting.online/branding/swagger-ui/index.html#/
- Report Swagger UI - https://automationintesting.online/report/swagger-ui/index.html#/
- Message Swagger UI - https://automationintesting.online/message/swagger-ui/index.html#/
For the system we are testing, I've linked all the Swagger API endpoint pages, you'll notice when visiting the swagger ui page, there is link to the OpenAPI Spec. This is the spec file
Now we have the urls to the OpenAPI Spec files we can start building out out logic. I'll start by creating a file in the lib/helpers directory named coverage.ts. I'll use this to build out the logic needed.
Getting the OpenAPI Spec
The first step I tackled was downloading the OpenAPI spec file. I wanted to do this for multiple files knowing there are multiple endpoints that I want to parse and measure. So I created a function that can be called multiple times. The async function fetchOpenAPI takes a parameter of the resource as a string to indicate which OpenAPI spec we want to download, and uses the built in request method from the playwright library. Once the api call is made I take the response which is json and write the OpenAPI Spec file to the root directory using the writeFile function (this is more for reference and testing as we don't use this file for the moment). The fetchOpenAPI then returns the JSON body which we can use to parse and get the information we need in the next section.
import { request } from "@playwright/test";
import * as fs from "fs";
import "dotenv/config";
let baseURL = process.env.URL;
/**
*
* @param resource
* @returns JSON object of the OpenAPI spec
*
* @example await fetchOpenApi("messages"); returns JSON object of the OpenAPI spec
*
* There is also a ${resource}_spec3.json file created in the root of the project
* These files are used to get the endpoints and calculate coverage
*
*/
export async function fetchOpenApi(resource: string) {
const requestContext = await request.newContext();
const response = await requestContext.get(
`${baseURL}${resource}/v3/api-docs/${resource}-api`,
{ timeout: 5000 }
);
const body = await response.json();
writeFile(`./${resource}_spec3.json`, JSON.stringify(body, null, 2));
return body;
}
// eslint-disable-next-line
function writeFile(location: string, data: string) {
try {
fs.writeFileSync(location, data);
// console.log("File written successfully");
// console.log("The written file has" + " the following contents:");
// console.log("" + fs.readFileSync(location));
} catch (err) {
console.error(err);
}
}
Getting the Individual Endpoints
From the previous step we have the body of the JSON of the OpenAPI spec. An example of that file can be found at the Auth API spec. The next thing we need to do is parse this file and get the endpoints out of the file. We will write a function named getEndpoints that takes a json object as a parameter. We first go and grab the methods (verbs GET, PUT, POST, DELETE, etc) and then get the urlPath for each endpoint in the OpenAPI spec file. We then create an array with the verb space path. The output of the auth endpoints are
[ 'POST /auth/validate', 'POST /auth/logout', 'POST /auth/login' ]
Below is the code that generates the array.
/**
*
* @param json JSON object of the OpenAPI spec
* @returns Array of endpoints with format "VERB PATH"
* @example getEndpoints(authJson); returns ["POST /auth/login", "POST /auth/logout", ...]
*
* This function is used to get the endpoints from the OpenAPI spec
*/
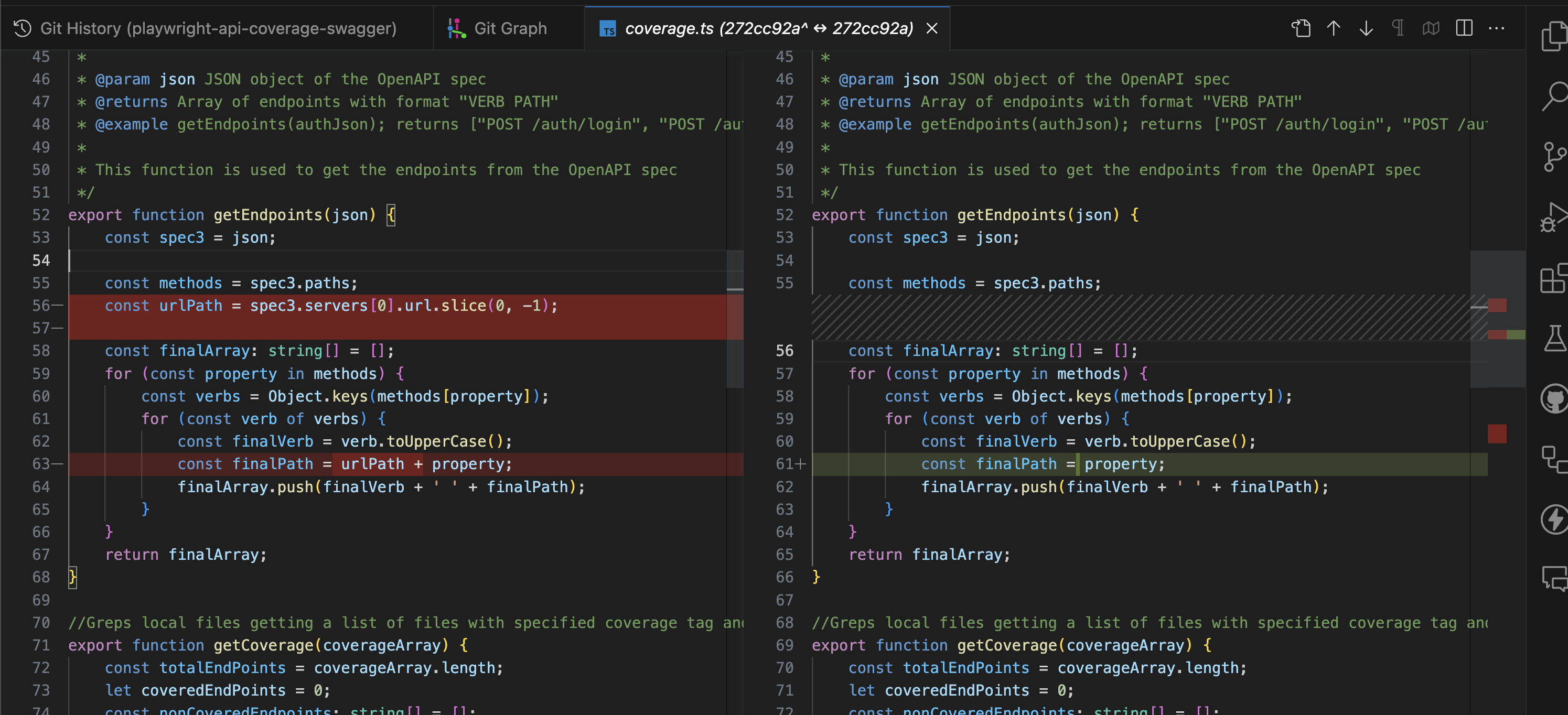
export function getEndpoints(json) {
let spec3 = json;
let methods = spec3.paths;
let urlPath = spec3.servers[0].url.slice(0, -1);
let finalArray: string[] = [];
for (const property in methods) {
let verbs = Object.keys(methods[property]);
for (const verb of verbs) {
let finalVerb = verb.toUpperCase();
let finalPath = urlPath + property;
finalArray.push(finalVerb + " " + finalPath);
}
}
return finalArray;
}
For example if you were writing tests against https://api.practicesoftwaretesting.com/docs/api-docs.json, which returns has the entire API in 1 OpenApi spec file, some of the code changes. For starters a full url for the server object, you can edit the file as follows, this will remove the urlPath code. You would also only have to make 1 call to calculate coverage await getEndpointCoverage('api') rather than making a call for each OpenApi spec.
Get Endpoint Coverage From Tests and Calculate Coverage
Now that we have what endpoints exist within the OpenAPI Spec file, we need to do a comparison with our own codebase to see what endpoints have coverage. To do this we are going to utilize the coverage tags which were covered earlier in this article example: //COVERAGE_TAG: GET /booking/. The function we will use is getCoverage that requires an array, we will use the previous array that we just built). The function iterates through the coverage array, and for each value, runs a grep command searching the files in the /tests/ directory to attempt to match to an existing coverage tag. It does this using the execSync function and will require your base system to have grep installed and accessible from the command line.
const output = execSync(
`grep -rl tests -e 'COVERAGE_TAG: ${coverageArray[value]}$' | cat`,
{
encoding: "utf-8",
}
)The command "grep -rl" searches for a specific text pattern recursively in all files and directories under a specified directory and returns the names of the files that contain the pattern. The "-r" option tells grep to search recursively, and the "-l" option tells it to only print the names of the files that contain the pattern, rather than the actual lines that match.
If there is a match we add a value to coveredEndpoints (which starts from 0) and if there isn't a match, we add that value to a nonCoveredEndpoints array, and console.log out a message that this endpoint is missing coverage.
After iterating through all the values, we calculate the coverage with the amount of coveredEndpoints and totalEndpoints and print this out via console messages. The code for this is in the calculateCoverage function below.
import { execSync } from "child_process";
//Greps local files getting a list of files with specified coverage tag and calculates coverage
export function getCoverage(coverageArray) {
let totalEndPoints = coverageArray.length;
let coveredEndPoints = 0;
let nonCoveredEndpoints: string[] = [];
//Iterates through the coverageArray to grep each file in the test directory looking for matches
for (const value in coverageArray) {
const output = execSync(
`grep -rl tests -e 'COVERAGE_TAG: ${coverageArray[value]}$' | cat`,
{
encoding: "utf-8",
}
);
// console.log(value);
// console.log(coverageArray[value]);
// console.log(output);
if (output != "") {
coveredEndPoints += 1;
} else {
console.log(`Endpoint with no coverage: ${coverageArray[value]}`);
nonCoveredEndpoints.push(coverageArray[value]);
}
}
console.log("Total Endpoints: " + totalEndPoints);
console.log("Covered Endpoints: " + coveredEndPoints);
// writeFile(
// "./lib/non_covered_endpoints.txt",
// JSON.stringify(nonCoveredEndpoints, null, "\t")
// );
calculateCoverage(coveredEndPoints, totalEndPoints);
}
function calculateCoverage(coveredEndpoints: number, totalEndpoints: number) {
let percentCovered = ((coveredEndpoints / totalEndpoints) * 100).toFixed(2);
console.log("Coverage: " + percentCovered + "%");
process.env.COVERED_ENDPOINTS = coveredEndpoints.toString();
process.env.TOTAL_ENDPOINTS = totalEndpoints.toString();
process.env.PERCENT_COVERED = percentCovered.toString();
}
Creating a Function That Calls All the Other Functions
I'll admit my naming hasn't been the best, and could be better, along with some of the functions that I've included so far. I'm sure they could be refactored to be much nicer. This next section I've created a function called getEndpointCoverage and it is the only function I am exporting in the coverage file (our entry point). This function only needs the endpoint name, as I am setting the baseURL from the dotenv config file. This function calls fetchOpenApi, getEndpoints, and getCoverage functions.
import "dotenv/config";
let baseURL = process.env.URL;
/**
*
* @param endpoint url path for pulling the OpenAPI spec
* @example getEndpointCoverage("auth"); console logs coverage for auth endpoints
*/
export async function getEndpointCoverage(endpoint: string) {
console.log(`=== Coverage for ${endpoint} Endpoints ===`);
let response = await fetchOpenApi(endpoint);
let coverageArray = getEndpoints(response);
getCoverage(coverageArray);
}
After this function is run you will get nice output in your terminal with details for the endpoints you have coverage for.
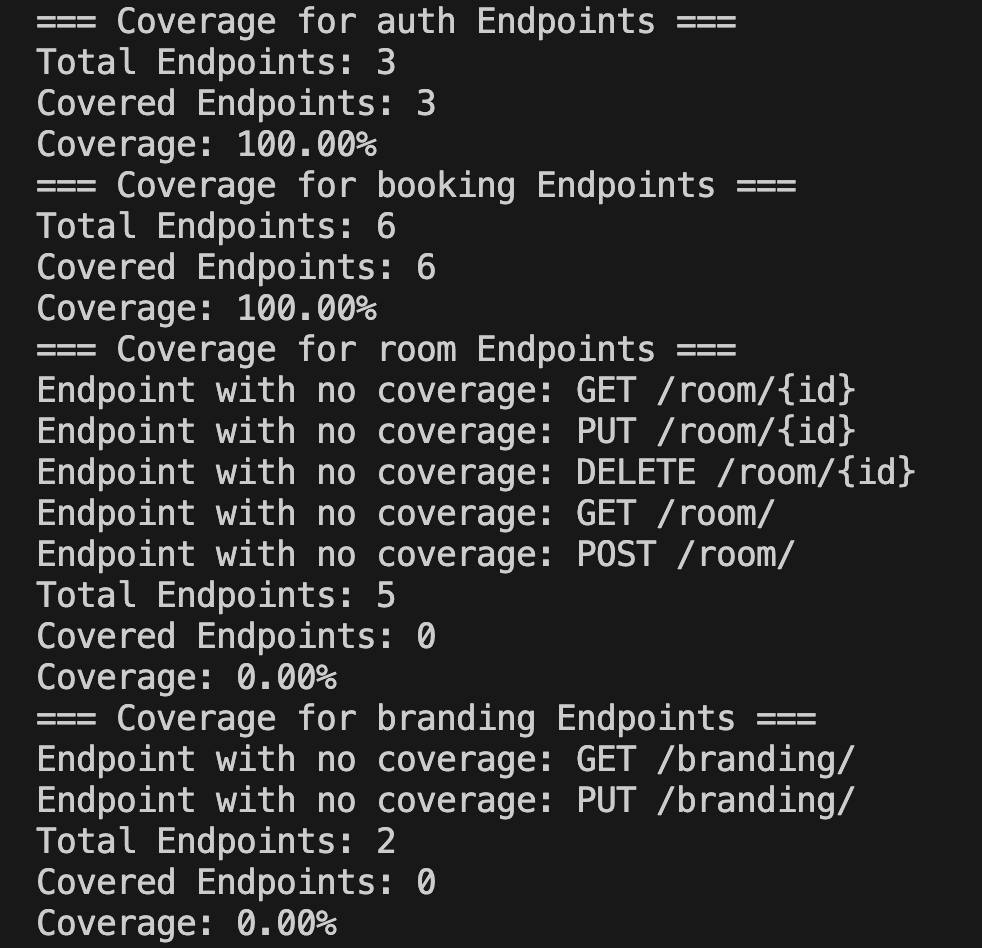
The complete coverage.ts file can be found in it's entirety below. We still need to create a way to call this function before all our tests run, which I'll cover after the code block.
// lib/helpers/coverage.ts
import { request } from "@playwright/test";
import * as fs from "fs";
import { execSync } from "child_process";
import "dotenv/config";
let baseURL = process.env.URL;
/**
*
* @param endpoint url path for pulling the OpenAPI spec
* @example getEndpointCoverage("auth"); console logs coverage for auth endpoints
*/
export async function getEndpointCoverage(endpoint: string) {
console.log(`=== Coverage for ${endpoint} Endpoints ===`);
let response = await fetchOpenApi(endpoint);
let coverageArray = getEndpoints(response);
getCoverage(coverageArray);
}
/**
*
* @param resource
* @returns JSON object of the OpenAPI spec
*
* @example await fetchOpenApi("messages"); returns JSON object of the OpenAPI spec
*
* There is also a ${resource}_spec3.json file created in the root of the project
* These files are used to get the endpoints and calculate coverage
*
*/
export async function fetchOpenApi(resource: string) {
const requestContext = await request.newContext();
const response = await requestContext.get(
`${baseURL}${resource}/v3/api-docs/${resource}-api`,
{ timeout: 5000 }
);
const body = await response.json();
writeFile(`./${resource}_spec3.json`, JSON.stringify(body, null, 2));
return body;
}
/**
*
* @param json JSON object of the OpenAPI spec
* @returns Array of endpoints with format "VERB PATH"
* @example getEndpoints(authJson); returns ["POST /auth/login", "POST /auth/logout", ...]
*
* This function is used to get the endpoints from the OpenAPI spec
*/
export function getEndpoints(json) {
let spec3 = json;
let methods = spec3.paths;
let urlPath = spec3.servers[0].url.slice(0, -1);
let finalArray: string[] = [];
for (const property in methods) {
let verbs = Object.keys(methods[property]);
for (const verb of verbs) {
let finalVerb = verb.toUpperCase();
let finalPath = urlPath + property;
finalArray.push(finalVerb + " " + finalPath);
}
}
return finalArray;
}
//Greps local files getting a list of files with specified coverage tag and calculates coverage
export function getCoverage(coverageArray) {
let totalEndPoints = coverageArray.length;
let coveredEndPoints = 0;
let nonCoveredEndpoints: string[] = [];
//Iterates through the coverageArray to grep each file in the test directory looking for matches
for (const value in coverageArray) {
const output = execSync(
`grep -rl tests -e 'COVERAGE_TAG: ${coverageArray[value]}$' | cat`,
{
encoding: "utf-8",
}
);
// console.log(value);
// console.log(coverageArray[value]);
// console.log(output);
if (output != "") {
coveredEndPoints += 1;
} else {
console.log(`Endpoint with no coverage: ${coverageArray[value]}`);
nonCoveredEndpoints.push(coverageArray[value]);
}
}
console.log("Total Endpoints: " + totalEndPoints);
console.log("Covered Endpoints: " + coveredEndPoints);
// writeFile(
// "./lib/non_covered_endpoints.txt",
// JSON.stringify(nonCoveredEndpoints, null, "\t")
// );
calculateCoverage(coveredEndPoints, totalEndPoints);
}
function calculateCoverage(coveredEndpoints: number, totalEndpoints: number) {
let percentCovered = ((coveredEndpoints / totalEndpoints) * 100).toFixed(2);
console.log("Coverage: " + percentCovered + "%");
process.env.COVERED_ENDPOINTS = coveredEndpoints.toString();
process.env.TOTAL_ENDPOINTS = totalEndpoints.toString();
process.env.PERCENT_COVERED = percentCovered.toString();
}
// eslint-disable-next-line
function writeFile(location: string, data: string) {
try {
fs.writeFileSync(location, data);
// console.log("File written successfully");
// console.log("The written file has" + " the following contents:");
// console.log("" + fs.readFileSync(location));
} catch (err) {
console.error(err);
}
}
Thanks to Dmitry Pakhilov for suggestions on how to make the code more readable!
Calculate Coverage Using defineConfig
We will be using the defineConfig function that allows us to utilize the test runner and setup and create order to our tests. Below is an example of a file I created named coverage.setup.ts Notice, this file isn't using the spec in the name but rather setup, this will allow us to separate our setup versus spec files.
notice we are also renaming test as coverage This naming convention is really just so we can better describe our actions. We will uset the same syntax as when writing tests with the async block and will call getEndpointCoverage() function for each of our API endpoints.
// tests/coverage.setup.ts
import { getEndpointCoverage } from "../lib/helpers/coverage";
import { test as coverage } from "@playwright/test";
coverage("calculate coverage", async () => {
await getEndpointCoverage("auth");
await getEndpointCoverage("booking");
await getEndpointCoverage("room");
await getEndpointCoverage("branding");
await getEndpointCoverage("report");
await getEndpointCoverage("message");
});
Below is the playwright.config.ts file. You can see in the projects section there are 2 objects in the array, the first is named setup and the 2nd is named api-checks. For the setup project I create a testMatch that will only run the coverage.setup.ts file. The api-checks is using the dependencies which requires setup to complete before running.
// playwright.config.ts
import { defineConfig } from "@playwright/test";
import { config } from "dotenv";
config();
export default defineConfig({
projects: [
{ name: "setup", testMatch: /coverage.setup.ts/ },
{
name: "api-checks",
dependencies: ["setup"],
},
],
use: {
extraHTTPHeaders: {
"playwright-solutions": "true",
},
baseURL: process.env.URL,
ignoreHTTPSErrors: true,
trace: "on",
},
retries: 0,
reporter: [["list"], ["html"]],
});
So Why Is This Important Again?
As you can see now when you run your tests, now you should have some really nice output for your API endpoint coverage. Now at this point (or probably way sooner) you may be asking why... Why should I do this? Well for me there are a few reasons. When first starting off a project I want to be able to track progress. Though my checks I am writing may still be mainly covering high level breadth of the endpoints (not going super deep on assertions), I want to be able to track my progress.
Having this tooling built into my framework also allows me to not just track what I've done today, but when I get coverage to 100%, and a new endpoint gets added, I'll know about it right away if I am checking the logs, if not I can easily take any new endpoints and alert a slack channel or have some other form of notification to alert me when new endpoints have been added. This has been a big help for me in my day job keeping up with new endpoints released. We have a goal to add coverage to any new endpoints added within a week.
The full codebase can be found below where you can download and run for yourself, or visit the GitHub pages link to view the results from the latest test run.
 playwrightsolutions
playwrightsolutionsIf you made it this far you are amazing. This is me celebrating together with you!

Thanks for reading! If you found this helpful, reach out and let me know on LinkedIn or consider buying me a cup of coffee. If you want more content delivered to you in your inbox subscribe below.